
Let’s first clarify the concept of ORC. OCR is the abbreviation for optical character recognition. It is a technology that can automatically convert text in images or scanned documents into editable electronic text. OCR allows computers to “see” and “understand” text content in images or documents, and then convert them into electronic text formats that can be edited and processed. For example, if you have a paper document with a lot of text on it and you want to convert it into a Word document or text file, you can use OCR technology. All you need to do is scan the paper document into an image, and then use OCR software to process it. It can automatically recognize the text in the image and convert it into editable electronic text.
How is OCR applied to industrial manufacturing?
In industrial production, OCR is used to identify text in industrial products through machine vision devices and systems. The vision system will perform various processing on the text captured by the vision device according to the instructions, such as comparing with the text set by the system, with or without text, identifying the date, recording text, etc., and using this data as a basis for classification, removal, re-labelling and other operations on industrial products.
Unlike characters printed on paper, characters on industrial products are more difficult to identify due to large differences in character carriers, possible reflections, small color differences between characters and background, and overlap between the character carrier pattern and characters.
Combined with the current deep learning model, the above tricky point can all be solved. It can accurately identify partially blocked, deformed, and reflective characters.
OCR procedure
In order to achieve accurate recognition, it is necessary to perform accurate text extraction and segmentation. The overall process of obtaining text from an image includes the following steps:
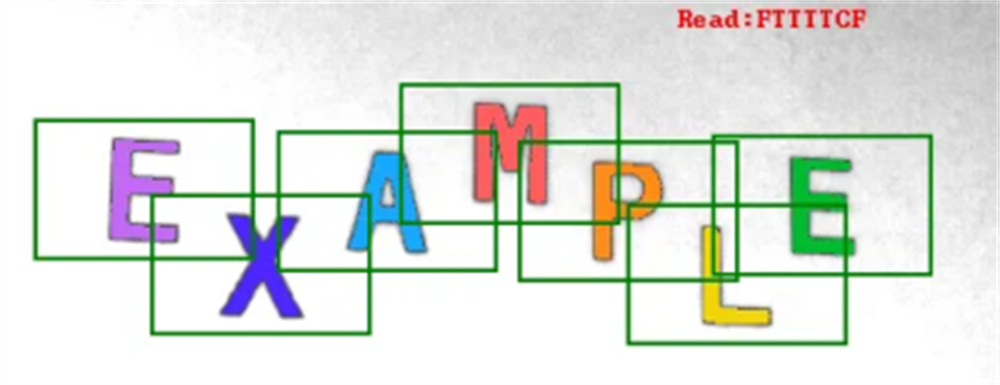
Reading text from an image.
Obtaining text location.
Extract text from the background.
Segmenting text.
Using a prepared OCR model to process the text.
Character recognition.
Get text position
There are three main types of text acquisition for different text states.
1. The position of the text is fixed. For example, a personal ID card is made according to certain specifications. The position of each data field is known. A well-calibrated visual system can capture images with fixed text positions.

2. The text position is not fixed, but is related to characteristic elements or special markers (optical markers) on the input image. To get the location of the text, optical markers must be found. This can be done through template matching, edge detection or other techniques.

3. Theposition of the text is not specified, but characters can be easily separated from the background by image thresholding. Blob analysis techniques can then be used to find the correct characters.

Extract text from the background.
The main complication during text extraction may be uneven lighting. Certain techniques like light normalization or edge sharpening help in character recognition.
Riginal image:

Image after processed:

Image after low frequency image damped by Fourier transform:

Image capture under uneven lighting:

Image after processed:


At this point, the extracted text region is ready for segmentation.
Segmenting text
Text region segmentation is the process of dividing regions into lines and individual characters. Recognition is only possible if each region contains a character.
The process of splitting text into lines using region morphological filters:

When each line of text is separated, the characters of each line must be split into individual ones.
Use split region to get character segmentation of multiple characters:

Next, the extracted characters are converted from the graphical representation to the text representation.
Calling the OCR Model Library
By calling the OCR model library, recognized characters are compared with the model library in text form, matching templates with similar data, and obtaining accurate character information.
Character recognition
In general, it is necessary to select an appropriate standard character size to classify the character size.
Character display:


Characters after standardization:
![]()
![]()








